INTRODUCTION
Data classification is as fundamental a part of securing an organization’s data and who can access it. It’s the process of identifying and assigning pre-determined levels of sensitivity or confidentiality to different types of data. If your organization doesn’t properly classify its data, then you cannot properly protect the data or prevent it from unauthorized access, use, disruption, modification or destruction whilst in storage.
From an Information Security perspective, the CIA Triad Model (Figure 1) is used to guide policies for information security within an organization:
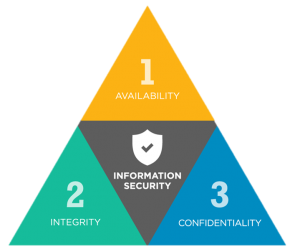
Figure 1
- Confidentiality:Confidentiality is roughly equivalent to privacy. Access must be restricted to those authorized only to view the data in question
- Integrity:Integrity involves maintaining data consistency; data must not be changed in transit and should be consistent throughout its entire lifecycle.
- Availability:Availability is making sure that the system is up and running and there isn’t any wear and tear due to hardware or software failure.
When viewed in the context of information security data classification will also enhance the performance of existing security systems and raise security awareness within the organization, which will, in turn, foster a security culture; affirm the relevance of information security; and add context and meaning to the information.
DATA CLASSIFICATION OVERVIEW
There are normally four steps required in the data classification process when implementing a data classification framework:
- Define the objectives of the data classification process.What are you looking for? Why?
- Create workflows based on the selected classification tools.How does the classification process work? Is there a process in place to scan new data? Is there a process to create new classification criteria?
- Define the categories and classification criteria.What kinds of data should you search for? What process will you follow to validate the classification results?
- Define outcomes and usage of classified data.How are the results organized – and how do you plan to make business decisions based on those results?
Data classification processes may differ slightly depending on the objectives and any data classification process requires automation to process the astonishing amount of data that companies create every day. With automation classifications are applied by solutions that use software algorithms based on keywords or phrases in the content to analyze and classify it. This approach comes into its own where certain types of data are created with no user involvement – for example reports generated by ERP systems or where the data includes specific personal information which is easily identified such as credit card details.
Beyond data security concerns, there can be several important reasons for implementing a data classification process such as:
- Identifying sensitive files, intellectual property, and trade secrets
- Securing (and lock down) of critical data
- Tracking regulated data to comply with regulations like HIPAA, PCI, or GDPR
- Optimizing search capabilities with data indexing
- Discovery of statistically significant patterns or trends inside data
- Optimizing storage by identifying duplicate or stale data
Obviously, as can be seen automation plays a significant role in this and there are several good software tools to choose from in the marketplace that have been designed specifically to address these aspects. Choosing the right automated solutions cannot be understated and should be chosen wisely and software vendor Client references must always be checked and confirmed before any decision is made to purchase.
For the purpose of this article we have assumed that Steps 1 and 2 of the data classification process have been completed and the focus will be on Step 3 of the process – Defining the classification and categories criteria.
The diagram below (Figure 2) illustrates a typical Data Sharing Policy Framework that has various elements within that would be responsible for sensitive data. Data classification provides a solid foundation for a data security strategy because it helps identify risky areas in the IT Governance Infrastructure, both on premises and in the cloud.
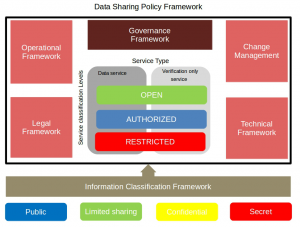
Figure 2
CLASSIFYING DATA
Data Classification is the process of analyzing structured or unstructured data and organizing it into categories based on the file type and contents.
Data classification enables an organization to determine and assign value to their data and provides a common starting point for governance. The data classification process categorizes data by sensitivity and business impact in order to identify risks. When data is classified, you can manage it in ways that protect sensitive or important data from theft or loss.
These classification categories within the framework will vary according to the type of industry the organization operates in and the product and/or service offering provided. An example framework is illustrated in the diagram (Figure 3) below.
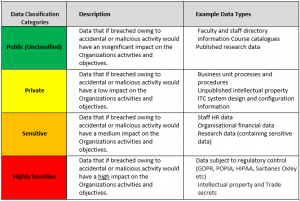
Figure 3
DATA CATEGORIES
Public (Unclassified) Data
Much of the data held by the organization is freely available to the public via established publication methods. Such items of information have no classification and will not be assigned a formal owner or inventoried.
It may be necessary however to maintain an awareness of the data that falls within this classification over time as circumstances may change and a need to provide increased protection of previously public data may arise.
Private Data
For data that is not published freely by the organization, some of this may be classified as Private. This is typically data, which is relatively private in nature, either to an individual or to the organization and, whilst its loss or disclosure is unlikely to result in significant consequences, it would be undesirable.
The criteria for assessing whether data would be classified as Private include whether its unauthorized disclosure would:
- Cause distress to individuals
- Breach proper undertakings to maintain the confidence of data provided by third parties
- Breach statutory restrictions on the disclosure of information
- Cause financial loss or loss of earning potential, or to facilitate improper gain
- Give an unfair advantage to individuals or companies
- Disadvantage the organization in commercial or policy negotiations with others
Most employees of the organization are likely to handle “Private” information during their working day.
Sensitive Data
The level above Private is that of Sensitive. This data would be more serious if it were disclosed to unauthorized persons and result in significant embarrassment to the organization and possibly legal consequences.
The criteria for assessing whether data would be classified as Sensitive include whether its unauthorized disclosure would:
- Affect relations with other organizations adversely
- Cause substantial distress to individuals
- Cause financial loss or loss of earning potential or to facilitate improper gain or advantage for individuals or companies
- Breach proper undertakings to maintain the confidence of data provided by third parties
- Impede the effective development or operation of organizational policies
- Breach statutory restrictions on disclosure of information
- Disadvantage the organization in commercial or policy negotiations with others
- Undermine the proper management of the organization and its operations
Information falling into the classification of “Sensitive” will typically be handled by middle management and above, with some employees of lower clearance being given access only in specific circumstances.
Highly Sensitive Data
The highest level of classification is that of Highly Sensitive. This is reserved for information which would cause major reputation and financial loss if it were lost or wrongly disclosed.
The criteria for assessing whether data would be classified as Highly Sensitive include whether its unauthorized disclosure would:
- Materially damage relations with other organizations (i.e. cause formal protest or other sanction)
- Cause damage to the operational effectiveness or security of the organization
- Work substantially against organizational finances or economic and commercial interests
- Substantially undermine the financial viability of major organizations
- Impede seriously the development or operation of organizational policies
- Shut down or otherwise substantially disrupt significant business operations
Access to data defined as “Highly Sensitive” must be tightly controlled by senior management and in many cases numbered copies of documents will be distributed according to specific procedures.
DECIDING THE CORRECT CLASSIFICATION
When deciding which classification to use for data, it is recommended that an assessment is conducted to consider the likely impact if the data were to be compromised.
A correct classification will ensure that only genuinely sensitive information is subject to additional controls.
The following points should be considered when assessing the classification to use:
- Applying too high a classification can inhibit access, lead to unnecessary and expensive protective controls, and impair the efficiency of the organization’s business.
- Applying too low a classification may lead to damaging consequences and compromise of the data.
- The compromise of larger sets of information of the same classification is likely to have a higher impact (particularly in relation to personal data) than that of a single instance. Generally, this will not result in a higher classification but may require additional handling arrangements. However, if the accumulation of that data results in a more sensitive data being created, then a higher classification should be considered.
- The sensitivity of data may change over time and it may be necessary to reclassify the data. For example, if a document is being de-classified or the labelling changed, the file should also be changed to reflect the highest labelling within it.
CONCLUSION
Right from the time data is created until its destruction it needs to be taken proper care of. By classifying the data, you can protect your data, store it properly and manage it well and remember to align the data classification process according to your own business needs.
When you employ the right information classification strategies for your organization it will help you increase your data awareness by better understanding which Data is sensitive that will result in better decision-making. Your data classification strategy is the cornerstone of successful and secure use of data in your organization. Hence, data classification is a game-changer for your business and organizational efficiency.
Data classification presents a simple solution to a complicated problem, with studies indicating it can address as much as 80 per cent of the issues for a very small cost when compared to other security products and services that are available.
Should you require any advice or assistance with your data classification processes or development of classification objectives, policies and procedures please contact us by email at info@synergygrc.com.
Alternatively you can also contact us via our Web Site at https://synergygrc.com or the Standards Talk Web Site at https://standardstalk.com/listings/risk-management-and-iso-grc-compliance-consulting-and-advisory.html
REFERENCES
https://www.privateprotocol.com/category/data-classification/
https://www.imperva.com/learn/data-security/data-classification/
https://www.varonis.com/blog/data-classification/
https://www.cleverism.com/qualitative-and-quantitative-data-collection-methods/
https://www.boldonjames.com/information-security-data-classification.html
Recent Comments